Headless Browser Downloads
Headless browser downloads for mods
Hi Folks,
A few months ago I introduced a convenience function for installing mods. I've improved this service by making it compatible with cloud storage services such as dropbox, google drive and sync.com. I've done this by reworking the download logic to take advantage of headless browsers.
What's the problem?
The problem presented by many cloud storage options is that the share link to the download often doesn't directly point to the download file. Rather it's a webpage with some metadata about the download with a button that needs to be clicked to start the download. This can be diffcult to consume with a http client, especialy if the response includes javascript that needs to be evaluated to navigate to the download.
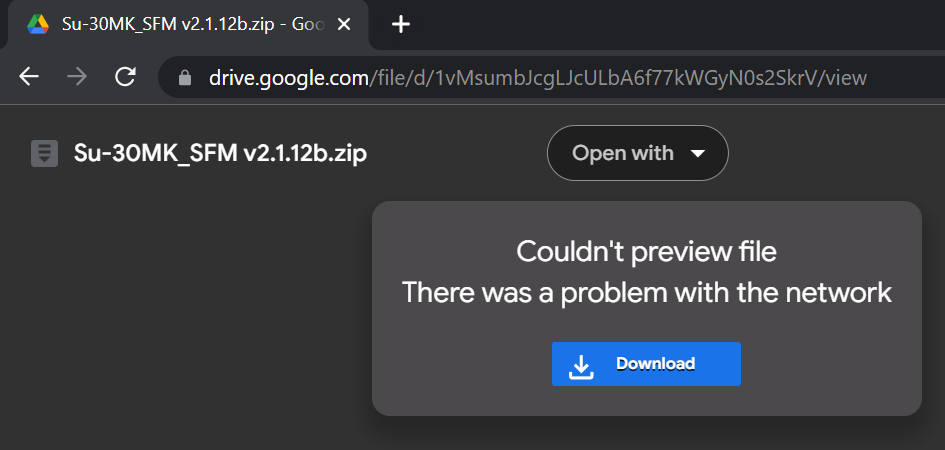
The SU30 mod is distributed via google drive
Headless Browsers
A headless browser is a web browser without a graphical user interface / that has an API (Abstract Programming Interafce), so a program can articulate instructions in much the same way a person would - i.e. find the 'Download' button and click it.
webDriver.findElement(By.cssSelector("button[id=download]")).click();
This frees the calling program from having to understand the details of interpreting the page and web interactions as it's being done by the headless browser.
Installing the SU30 mod
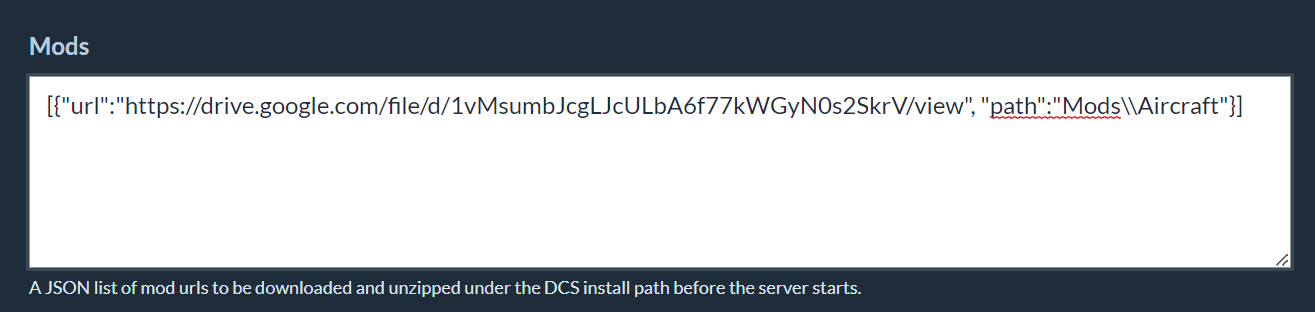
Using the SU30 Mod as an example, the following json can be supplied to the schedule form:
[{"url":"https://drive.google.com/file/d/1vMsumbJcgLJcULbA6f77kWGyN0s2SkrV/view", "path":"Mods\\Aircraft"}]
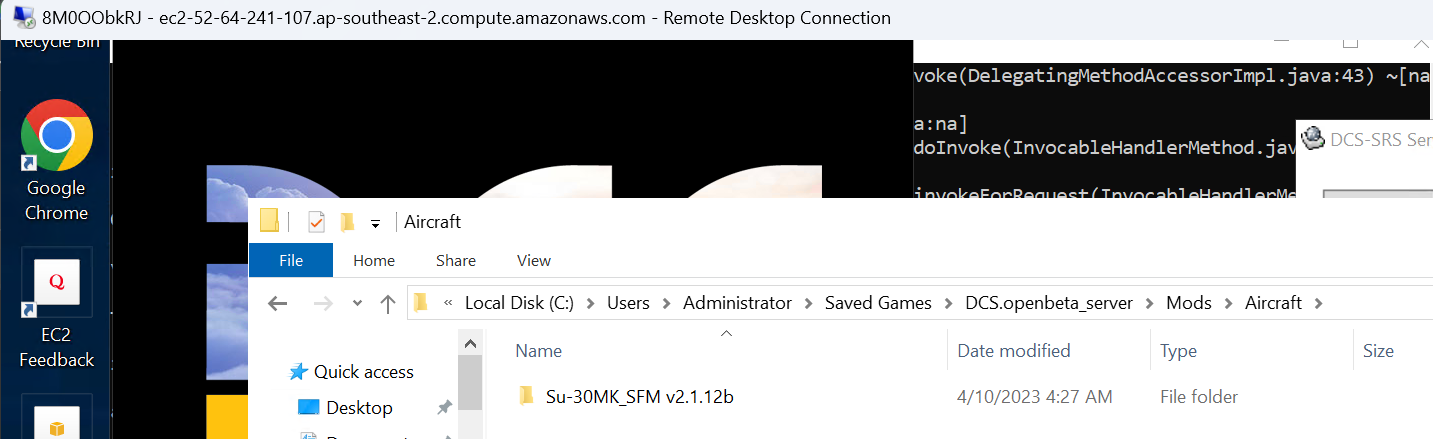
Connecting via RDP (Remote Desktop Protocol) after the mission has started we can verify the mod has been unpacked to C:\Users\Administrator\Saved Games\DCS.openbeta_server\Mods\Aircraft:
Implementation
The implementation I arrived at is uses a WatchService to monitor the browser's download directory for changes to notifiy when downloads start and complte, and queries the browser's download page to discover the file resolved from a given uri.
package readyroom;
import io.github.bonigarcia.wdm.WebDriverManager;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.Wait;
import org.openqa.selenium.support.ui.WebDriverWait;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import reactor.core.Disposable;
import reactor.core.publisher.ConnectableFlux;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import reactor.util.function.Tuple2;
import reactor.util.function.Tuples;
import java.io.IOException;
import java.nio.file.*;
import java.time.Duration;
import java.time.Instant;
import java.util.HashMap;
import java.util.List;
import java.util.Set;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static java.nio.file.StandardWatchEventKinds.*;
import static java.nio.file.StandardWatchEventKinds.ENTRY_CREATE;
public class HeadlessBrowserDownloads {
private static final Logger logger = LoggerFactory.getLogger(HeadlessBrowserDownloads.class);
public static class DownloadDirEvent {
private final Instant timestamp;
private final WatchEvent.Kind<?> kind;
private final Path path;
DownloadDirEvent(Instant timestamp, WatchEvent.Kind<?> kind, Path path) {
this.timestamp = timestamp;
this.kind = kind;
this.path = path;
}
public Instant getTimestamp() {
return timestamp;
}
public WatchEvent.Kind<?> getKind() {
return kind;
}
public Path getPath() {
return path;
}
@Override
public String toString() {
return "DownloadDirEvent{" +
"timestamp=" + timestamp +
", kind=" + kind +
", path=" + path +
'}';
}
}
public static Flux<DownloadDirEvent> watchDir(Path dir) throws IOException {
WatchService watcher = FileSystems.getDefault().newWatchService();
dir.register(watcher, ENTRY_CREATE, ENTRY_DELETE, ENTRY_MODIFY);
Flux<DownloadDirEvent> flux = Flux.interval(Duration.ofMillis(500))
.flatMap(i -> {
WatchKey key = watcher.poll();
if(key != null) {
List<WatchEvent<?>> events = key.pollEvents();
key.reset();
return Flux.fromIterable(events);
} else {
return Flux.empty();
}
}).map(watchEvent -> new DownloadDirEvent(Instant.now(), watchEvent.kind(), dir.resolve((Path) watchEvent.context())))
.doOnCancel(() -> {
// Infinite stream / normal mode of stopping
try {
watcher.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
});
return flux;
}
// Decorates a WebDriver wait as a Project Rector Mono
public static <T, V> Mono<V> waitMono(Wait<T> wait, Function<? super T, V> until) {
Mono<V> mono = Mono.create(monoSink -> monoSink.success(wait.until(until)));
return mono.subscribeOn(Schedulers.boundedElastic());
}
// Emits the original url with the path of the downloaded file as each download is completed
public static Flux<Tuple2<String, Path>> download(
List<String> uris,
ChromeDriver webDriver,
ConnectableFlux<DownloadDirEvent> downloadDirEvents,
Consumer<String> logMessages
) {
Mono<Void> syncDotCom = waitMono(
new WebDriverWait(webDriver, 10),
ExpectedConditions.elementToBeClickable(By.tagName("button"))
).flatMap(button -> Mono.fromRunnable(button::click));
Mono<Void> dropBox = waitMono(
new WebDriverWait(webDriver, 10),
ExpectedConditions.elementToBeClickable(By.cssSelector(".action-bar-action-DOWNLOAD_ACTION"))
).flatMap(button -> Mono.fromRunnable(button::click));
Mono<Void> googleDriveCantPreview = waitMono(
new WebDriverWait(webDriver, 10),
ExpectedConditions.elementToBeClickable(By.cssSelector("div[data-tooltip=Download]"))
).flatMap(button -> Mono.fromRunnable(() -> {
// Expecting a new tab
Set<String> handles = webDriver.getWindowHandles();
button.click();
webDriver.getWindowHandles().stream()
.filter(handle -> !handles.contains(handle))
.findFirst().ifPresent(handle -> webDriver.switchTo().window(handle));
}));
Mono<Void> googleDriveDownloadAnyway = waitMono(
new WebDriverWait(webDriver, 20),
ExpectedConditions.presenceOfElementLocated(By.tagName("form"))
).flatMap(form -> Mono.fromRunnable(form::submit));
Function<String, Stream<Mono<Void>>> strategiesForUri = uri -> {
if(uri.contains("dropbox.com")) {
return Stream.of(dropBox);
} else if(uri.contains("sync.com")) {
return Stream.of(syncDotCom);
} else if (uri.contains("drive.google.com")) {
return Stream.of(
googleDriveCantPreview.then(googleDriveDownloadAnyway),
googleDriveDownloadAnyway
);
} else {
return Stream.empty();
}
};
// Need to start downloads sequentially in order to correlate uris with resolved filenames
Flux<Tuple2<String, String>> startedDownloads = Flux.concat(Flux.fromIterable(uris)
.map(uri -> Mono.fromCallable(Instant::now).flatMap(started -> {
Mono<Void> downloadStarted = downloadDirEvents
.filter(event -> event.getTimestamp().isAfter(started))
.filter(event -> event.getKind().equals(ENTRY_CREATE) && event.getPath().toString().endsWith(".crdownload"))
.next().then().timeout(Duration.ofSeconds(20))
.onErrorMap(t -> new RuntimeException("Exception waiting for download to start for " + uri, t));
Mono<Tuple2<String, String>> uriAndFilename =
Mono.fromRunnable(() -> webDriver.get(uri))
.then(
Mono.firstWithSignal(
Stream.of(
strategiesForUri.apply(uri),
Stream.of(downloadStarted)
).flatMap(s -> s).collect(Collectors.toList())
)
)
// wait for chrome to start download
.then(downloadStarted)
// get resolved filename from chrome downloads page
.then(
Mono.fromRunnable(() -> webDriver.get("chrome://downloads/")).then(
waitMono(
new WebDriverWait(webDriver, 2),
ExpectedConditions.presenceOfElementLocated(By.cssSelector("downloads-manager"))
)
.map(WebElement::getShadowRoot)
.map(searchContext -> searchContext.findElements(By.cssSelector("downloads-item"))
.stream()
.map(item -> {
WebElement name = item.getShadowRoot().findElement(By.cssSelector("span[id=name]"));
return name.getText();
}).findFirst().get()
)
)
).map(filename -> Tuples.of(uri, filename));
return uriAndFilename;
}))).doOnNext(t -> logMessages.accept("Started download " + t.getT1() + " " + t.getT2()));
Flux<Mono<Tuple2<String, Path>>> completedDownloads = startedDownloads.map(t -> {
String uri = t.getT1();
String filename = t.getT2();
return downloadDirEvents
.filter(event -> event.getKind().equals(ENTRY_CREATE) && event.getPath().toString().endsWith(filename))
.map(DownloadDirEvent::getPath)
.map(path -> Tuples.of(uri, path))
.next();
});
// Emit each download as it completes
Flux<Tuple2<String, Path>> merged = Flux.merge(completedDownloads);
return merged.doOnNext(t -> logMessages.accept("Completed download " + t.getT1() + " " + t.getT2()));
}
public static ChromeDriver createChromeDriver(String downloadDirectory) {
ChromeDriver driver;
{
WebDriverManager.chromedriver().setup();
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless=new");
//https://stackoverflow.com/questions/34515328/how-to-set-default-download-directory-in-selenium-chrome-capabilities
var prefs = new HashMap<String, Object>();
prefs.put("download.default_directory", downloadDirectory); // Bypass default download directory in Chrome
prefs.put("safebrowsing.enabled", "false"); // Bypass warning message, keep file anyway (for .exe, .jar, etc.)
options.setExperimentalOption("prefs", prefs);
driver = new ChromeDriver(options);
}
return driver;
}
// Emits the original url with the path of the downloaded file as each download is completed
public static Flux<Tuple2<String, Path>> download(
List<String> uris,
String downloadDirectory,
Consumer<String> logMessages
) throws IOException {
ChromeDriver driver = createChromeDriver(downloadDirectory);
ConnectableFlux<DownloadDirEvent> downloadDirEvents = watchDir(Path.of(downloadDirectory)).replay(Duration.ofMinutes(1));
Disposable watchDirDisposable = downloadDirEvents.connect();
return download(
uris,
driver,
downloadDirEvents,
logMessages
)
.doAfterTerminate(() -> {
watchDirDisposable.dispose();
logger.info("WatchService disposed");
})
.doAfterTerminate(() -> {
driver.quit();
logger.info("WebDriver quit");
});
}
}
Cheers,
Noisy